
Medium
The CPU requirement for the GPQT GPU based model is lower that the one that are optimized for CPU. Llama-2-13b-chatggmlv3q4_0bin offloaded 4343 layers to GPU. The performance of an Llama-2 model depends heavily on the hardware. Its likely that you can fine-tune the Llama 2-13B model using LoRA or QLoRA fine-tuning with a single consumer GPU with 24GB of memory and using. Hello Id like to know if 48 56 64 or 92 gb is needed for a cpu setup Supposedly with exllama 48gb is all youd need for 16k Its possible ggml may need more..
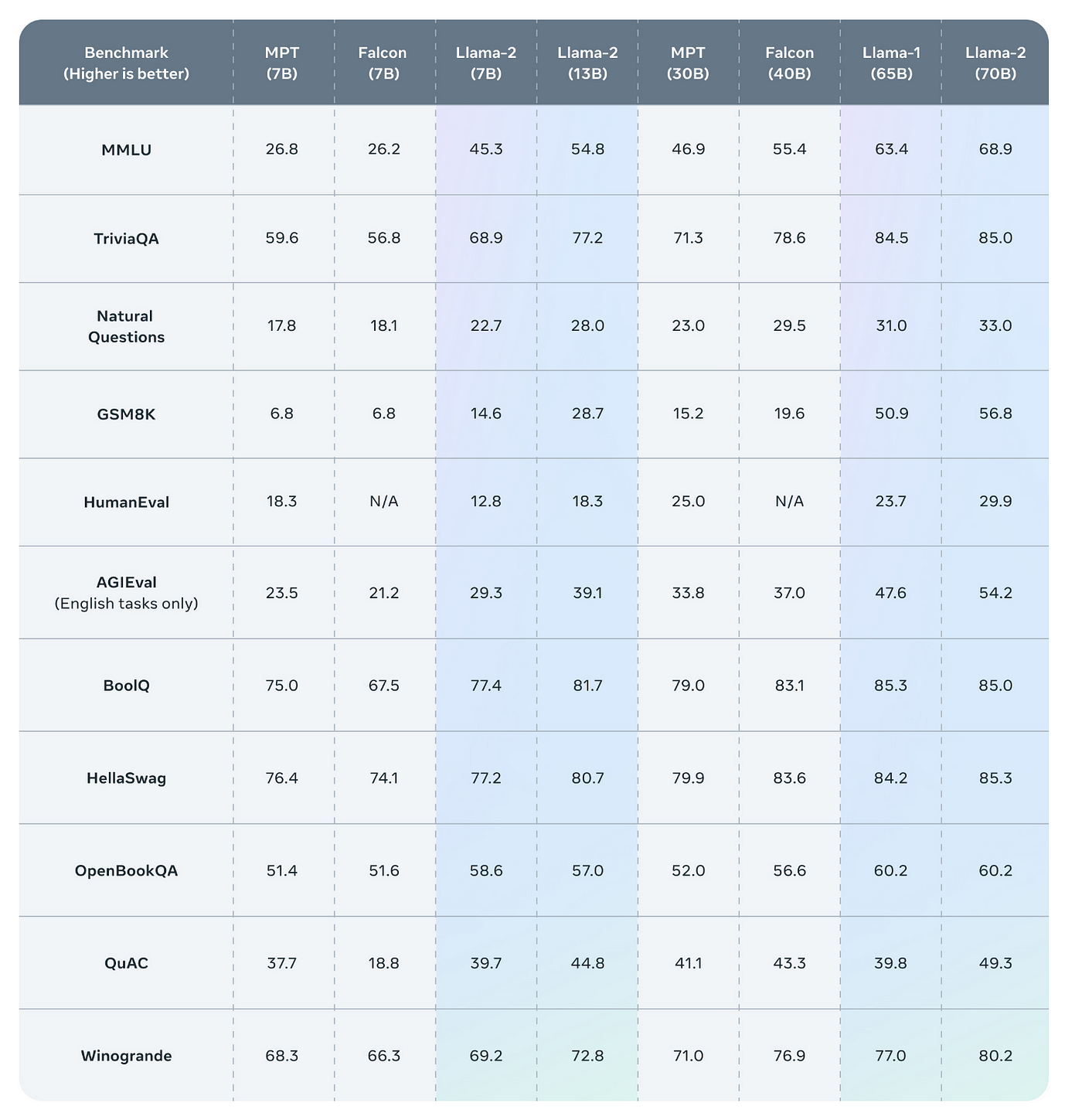
This release includes model weights and starting code for pretrained and fine-tuned Llama language models. Our latest version of Llama is now accessible to individuals creators researchers and businesses of all. Llama 2 outperforms other open source language models on many external benchmarks including reasoning. Llama 2 is a family of state-of-the-art open-access large language models released by Meta. Our fine-tuned LLMs called Llama 2-Chat are optimized for dialogue use cases. Takeaways Today were introducing the availability of Llama 2 the next generation of our open source. Code Llama is an AI model built on top of Llama 2 fine-tuned for generating and discussing code. Llama 2 We are unlocking the power of large language models Our latest version of Llama is now accessible to..
Chat with Llama 2 70B Customize Llamas personality by clicking the settings button I can explain concepts write poems and. Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Experience the power of Llama 2 the second-generation Large Language Model by Meta Choose from three model sizes pre-trained on 2 trillion tokens. Llama 2 7B13B are now available in Web LLM Try it out in our chat demo Llama 2 70B is also supported If you have a Apple Silicon. All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have double the context length of Llama 1..
Llama 2 encompasses a series of generative text models that have been pretrained and fine-tuned varying in size from 7 billion to 70 billion parameters. Model Developers Meta Variations Llama 2 comes in a range of parameter sizes 7B 13B and 70B as well as pretrained and fine-tuned variations. Llama-2-13b-chatggmlv3q4_0bin offloaded 4343 layers to GPU Similar to 79 but for Llama 2 Post your hardware setup and what model you. CodeUp Llama 2 13B Chat HF Description This repo contains GGUF format model files for DeepSEs CodeUp Llama 2 13B Chat HF About GGUF GGUF is a new format introduced by the. Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources The fine-tuning data includes publicly available instruction datasets as well as over one million..
Github
Comments